
In our fast-paced, digitally driven society, the demand for recording and transcribing conversations across various platforms—corporate meetings, podcasts, interviews, phone calls, online meetings, video conferences, or medical consultations—has skyrocketed. Yet, these conversations inherently engage many speakers and are significantly challenging to transcribe. Make way for speaker diarization, one of the most advanced technologies to solve this problem. Speaker diarization separates and isolates individual speakers from a recorded audio stream for accurate speech transcription.
This blog post discusses speaker diarization in detail, looking at its functionality, steps of operation, and main influence across several industries, especially in corporate meetings, podcasts, and interviews. Speaker diarization has become an integral part of the business and sectors working in our digital world to transcribe audio effectively, precisely, and accurately.
What is Speaker Diarization?

Speaker diarization is an AI-driven process essential for audio transcription, especially when handling recordings with multiple speakers. It involves separating speakers from audio to classify and distinguish individual voices within a sequence of sounds. By identifying who is speaking and segmenting their speech, speaker diarization makes transcripts more readable and easier to understand.
The technology hinges on two primary elements: speaker segmentation and speaker clustering. Speaker segmentation refers to the process of determining when one person finishes and another begins speaking, which is generally called speech change detection. The next step involves speech segment clustering, in which these segments are grouped together by matching them to the relevant speakers based on their distinctive audio properties. This procedure is like making audio ‘fingerprints’ for every participant in the conversation.
Why is Speaker Diarization Important?
By separating speakers from audio, diarization produces “split speakers” in a transcript. This enhances readability, making the content clear and easy to analyze or reference.
In scenarios like podcasts and interviews, where multiple voices overlap, speaker diarization is indispensable. It ensures listeners and readers can clearly identify who is speaking at any point, improving both the listening experience and the overall value of the content.
How Does Speaker Diarization Work?

Like any automated process, speaker diarization converts a mess of people talking into a clean and helpful transcript, but the methodology behind that technology needs to be clarified. The process begins by passing an audio file to a diarization system that can be one of the AI transcription services. This system executes several intricate operations to distinguish speakers.
To begin with, it de-separates speech from non-speech segments, eliminating background noise and music or silence. The essential step that follows is the detection of change points speakers. It does, so in this case, by analyzing the audio to highlight instances when one speaker pauses and another takes over. This entails identifying nuanced changes in voice characteristics, including pitch, tone, and speech style.
The system then groups the segments into clusters specific to speakers. It’s like sorting a mixed pile of conversation snippets into distinct baskets, each representing a unique speaker. The advanced algorithms use voice features to ensure all segments for one speaker are grouped.
Finally, the system labels each speaker through association with discrete segments in a transcript. This means you can see who said what and when in a podcast or interview. For instance, “Speaker 1: Speaker 2: [text] and so on. Such transcription helps to make the dialogue understandable and assists in speakers’ behavior, contribution, and interaction analysis).
Speaker diarization has the power to handle challenging audio environments with multiple speakers, overlapped speech, and varying quality. This is a game-changer for anyone who needs to transcribe podcasts, interviews, meetings, or any multi-speaker audio into clean and correct speaker-separated text.
The Benefits of Speaker Diarization:

Enhancing Clarity in Transcripts
Speaker diarization significantly improves the clarity of transcripts, particularly in scenarios like podcasts and interviews, where precision is essential. By distinguishing and labeling individual speakers, diarization eliminates confusion about who said what, making transcripts easier to read and understand.
Better Understanding of Conversation Dynamics
Speaker diarization provides deeper insights into the background and flow of conversations. Attributing quotes and ideas to the correct speaker ensures journalistic accuracy and enhances audience comprehension. This is particularly valuable for analyzing group dynamics—such as identifying dominant speakers and understanding how participants interact or respond during discussions.
Increased Accessibility in Education and Work Environments
In educational and professional settings, speaker diarization improves accessibility and clarity.
- Education: In online learning environments, students can easily differentiate between instructor comments and those from peers, enhancing their learning experience.
- Business Meetings: Diarization helps trace contributions and efforts, ensuring accountability and facilitating follow-up actions.
Supporting Data Analytics and Insights
Speaker diarization plays a crucial role in data analytics. Separating speakers makes it possible to analyze speech patterns, sentiment, and topic changes with greater precision. This capability is particularly valuable in:
- Market Research: Enabling detailed analysis of customer feedback.
- Customer Service: Assessing customer interactions to improve service quality and identify key trends.
Saving Time and Resources with Automation
Automation in speaker diarization reduces transcription resources and time required while significantly improving accuracy. This is especially beneficial when handling large volumes of audio data, where manual transcription is time-consuming and prone to errors.
Common Use Cases of Speaker Diarization:

The critical application of speaker diarization lies in the possibility of unwrapping and classifying multi-speak audio content using various sectors. Here are some of the most common use cases:
- News and Broadcasting: Speaker diarization can be used in news and broadcast media to record and archive newscasts. It facilitates the creation of accurate and searchable transcripts, which is essential for journalists and researchers. Secondly, it helps in video captioning to ensure viewers can follow the person talking at a time.
- Marketing and Call Centers: Speaker diarization is a valuable tool for marketing teams during brainstorming sessions, interviews, and client meetings, where each participant’s input can be recorded and analyzed later. In call centers, it helps in transcribing calls that offer necessary information about customer interactions, providing details on agent performance and quality assurance.
- Legal Sector: Speaker diarization is very significant regarding legal contexts for clarity. It ensures that every word of each side during depositions, hearings, or client meetings is correctly recorded because it may be necessary for case preparations and evidence.
- Healthcare and Medical Services: Diarization helps to provide an accurate record of patient consultations for medical personnel, which may be useful in developing treatment plans and guiding education and research. It also ensures that communications between patients and providers are properly documented for subsequent reference.
- Software Development and AI: Speaker diarization improves voice assistants and chatbot performances in artificial intelligence and software development. These tools can provide more personalized and accurate answers for a smart home device and a customer service bot knowing who is speaking.
- Recruiting and Human Resources: Recruiters must also create a record of their discussions with candidates, which will allow them to evaluate the interaction itself, assess compliance, and find biases. Due to speaker diarization, this process becomes easy and straightforward.
- Sales and Customer Service: In sales, it is important to understand the dynamics of a meeting. Diarization makes it possible to pinpoint the points of agreement, dissent, or uncertainty, allowing sales teams to create better strategies and train employees more effectively.
- Conversational AI in Customer Service: For voice bots in service, such as for taking food orders, speaker diarization allows differentiation between voices and processing only one customer’s demand.
- Education: This helps in transcribing lectures, discussions, and student interactions, among other things, in an educational setting, especially distance learning; it favors both students and educators when reviewing comprehension.
Speaker diarization is a multifaceted tool that improves the speed and accuracy of audio transcription in many sectors. It is not merely about splitting speakers; it pertains to releasing spoken data’s full power.
Top Softwares for Speaker Diarization:

Given the many speaker diarization tools, navigating their diversity can be challenging. Here are some top tools that have established themselves as leaders in the field, known for their accuracy and ease of use:
Clipto.AI – Transcription tool with Speaker Diarization
Clipto.AI is a recommended tool for speaker diarization, known for its simplicity and efficiency. Designed with podcasters and interviewers in mind, it streamlines audio processing with effortless integration and minimal manual effort.
Pros
- User-Friendly Interface: Clipto is designed for simplicity, making it accessible even to users with no technical expertise. Its intuitive interface reduces the learning curve.
- Effortless Integration: The tool seamlessly integrates into existing workflows, allowing podcasters and interviewers to process audio files quickly without extra setup or complex configurations.
- Efficiency in Speaker Separation: Clipto effectively separates speakers from audio, making it easier to generate clean, readable transcripts. This is particularly valuable for podcasts, interviews, and storytelling content.
- Time-Saving: With minimal manual intervention required, Clipto accelerates the diarization and transcription process, saving significant time for users working with large volumes of content.
- Cost-Effective Solution: Compared to larger enterprise tools, Clipto offers a more affordable option for small businesses, independent creators, and content producers.
Cons
- Limited Scalability: While excellent for podcasters and small teams, Clipto may not handle large-scale audio data or multi-speaker events as effectively as enterprise-level solutions.
- Fewer Advanced Features: Unlike tools such as IBM Watson or Google Cloud, Clipto focuses on simplicity, which means fewer customization options for industry-specific terms or accents.
IBM Watson’s Speech-Text API
IBM Watson is notable for its live speaker diarization component. It identifies and labels various speakers from an audience, making it one of the handiest tools for live events and broadcasts.
Pros
- Live Speaker Diarization: Watson accurately separates speakers from audio in real time, ideal for webinars, conferences, and broadcasts.
- High Accuracy: It performs well in complex environments, handling diverse speakers and overlapping speech.
- Customizable Models: Users can train the API to recognize industry-specific terms and accents, improving transcription accuracy.
- Scalable and Versatile: It supports both small meetings and large events, with seamless integration across platforms.
Cons
- Cost: The API can be expensive for smaller businesses, especially for large-scale events.
- Audio Quality Dependence: Accuracy may drop with poor audio input or excessive background noise.
- Technical Complexity: Advanced features require some technical knowledge for setup and customization.
- Internet Dependency: A stable connection is needed for real-time processing, which may be challenging in certain locations.
Amazon Transcribe
Amazon Transcribe is a powerful tool that can separate two to ten speakers from a single audio stream. With its high accuracy in recognizing speakers, it is particularly valuable for business meeting transcriptions, interviews, and customer service recordings.
Pros
- Speaker Separation: Amazon Transcribe effectively separates speakers from audio, handling up to ten speakers in a single recording. This makes it ideal for meetings, panel discussions, and interviews.
- High Accuracy: The tool delivers reliable speaker recognition and transcription quality, even in multi-speaker environments, improving usability for professional and business settings.
- Scalable Solution: It handles both small-scale and large-scale audio transcription needs, making it suitable for businesses of all sizes.
- Integration with AWS Ecosystem: Amazon Transcribe integrates seamlessly with other AWS tools and services, offering flexibility for developers and businesses already using the AWS ecosystem.
- Ease of Use: The platform is user-friendly, requiring minimal setup, making it accessible to users without deep technical expertise.
Cons
- Cost for Large Volumes: While affordable for smaller projects, costs can add up quickly for large-scale or continuous audio transcription.
- Accuracy Dependent on Audio Quality: Like most tools, Amazon Transcribe’s accuracy decreases when audio quality is poor, with significant background noise or unclear speech.
- Limited Speaker Customization: Compared to some competitors, there is limited ability to customize models for specific industry vocabularies or accents.
- Internet Dependency: As a cloud-based tool, a reliable internet connection is necessary for processing audio data, which may be a challenge in some settings.
Google Cloud Speech-to-Text
Google’s tool has speaker diarization capabilities of up to 10 voices across diverse languages. Its broad scope makes it suitable for international businesses and several dialects.
Pros
- Multi-Speaker Diarization: Google’s tool effectively separates speakers from audio, accommodating up to 10 distinct voices. This is ideal for meetings, podcasts, and conferences with multiple participants.
- Extensive Language Support: With support for numerous languages and dialects, it caters to global businesses and multilingual use cases. This makes it particularly useful for international teams and cross-border operations.
- High Accuracy in Speech Recognition: Google leverages its advanced machine learning algorithms to deliver accurate transcriptions, even in challenging audio environments.
- Integration with Google Cloud Ecosystem: The tool integrates seamlessly with other Google Cloud services, providing flexibility for businesses using Google’s ecosystem.
- Scalable and Reliable: Google Cloud Speech-to-Text is highly scalable, suitable for both small audio transcriptions and large-scale, multi-speaker projects.
Cons
- Cost for Extensive Use: While cost-effective for smaller tasks, continuous or large-scale transcriptions can become expensive for businesses with high audio processing needs.
- Audio Quality Dependency: Accuracy is impacted by background noise, overlapping speech, or low-quality recordings, similar to other tools in this niche.
- Limited Customization: While versatile, Google’s tool offers fewer customization options compared to competitors like IBM Watson or Amazon Transcribe for industry-specific terms and accents.
- Internet Connection Required: As a cloud-based service, it requires a stable internet connection for real-time processing, which can be a limitation in certain regions or environments.
How to use Clipto for speaker diarization in a corporate meeting, podcast or interview:
The main strength of Clipto Speaker Diarization is its applicability to podcasts and interviews. Here’s a simple guide to help you navigate the process:
- Uploading Your Audio/Video File: First, log in to your Clipto account and upload the audio or video file you would like transcribed. Clipto is compatible with different file formats, making it flexible for all types of recording.
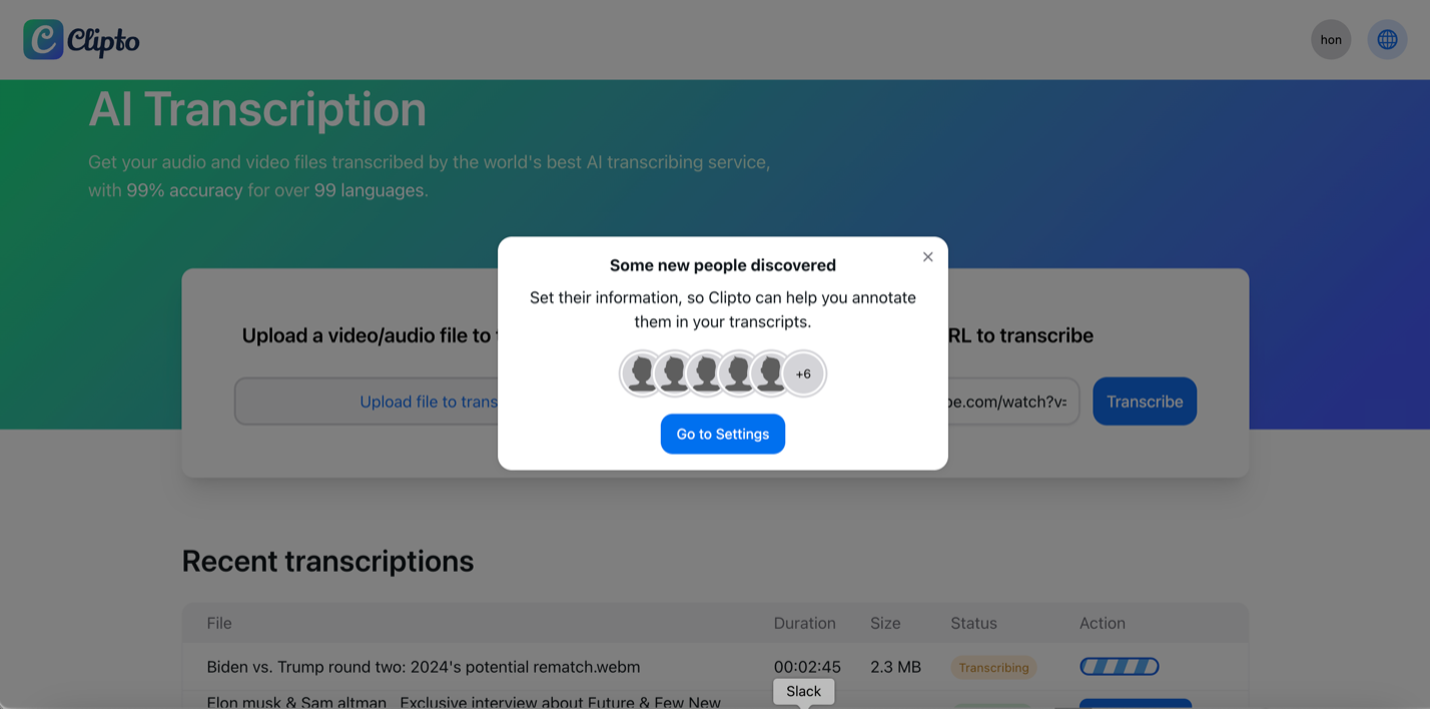
- Automatic Speaker Discovery: Clipto’s AI-based system automatically examines the audio after uploading. It can recognize various speakers in the file, distinguishing their voices based on unique features. This process happens automatically without any manual input so that you can save time and effort.
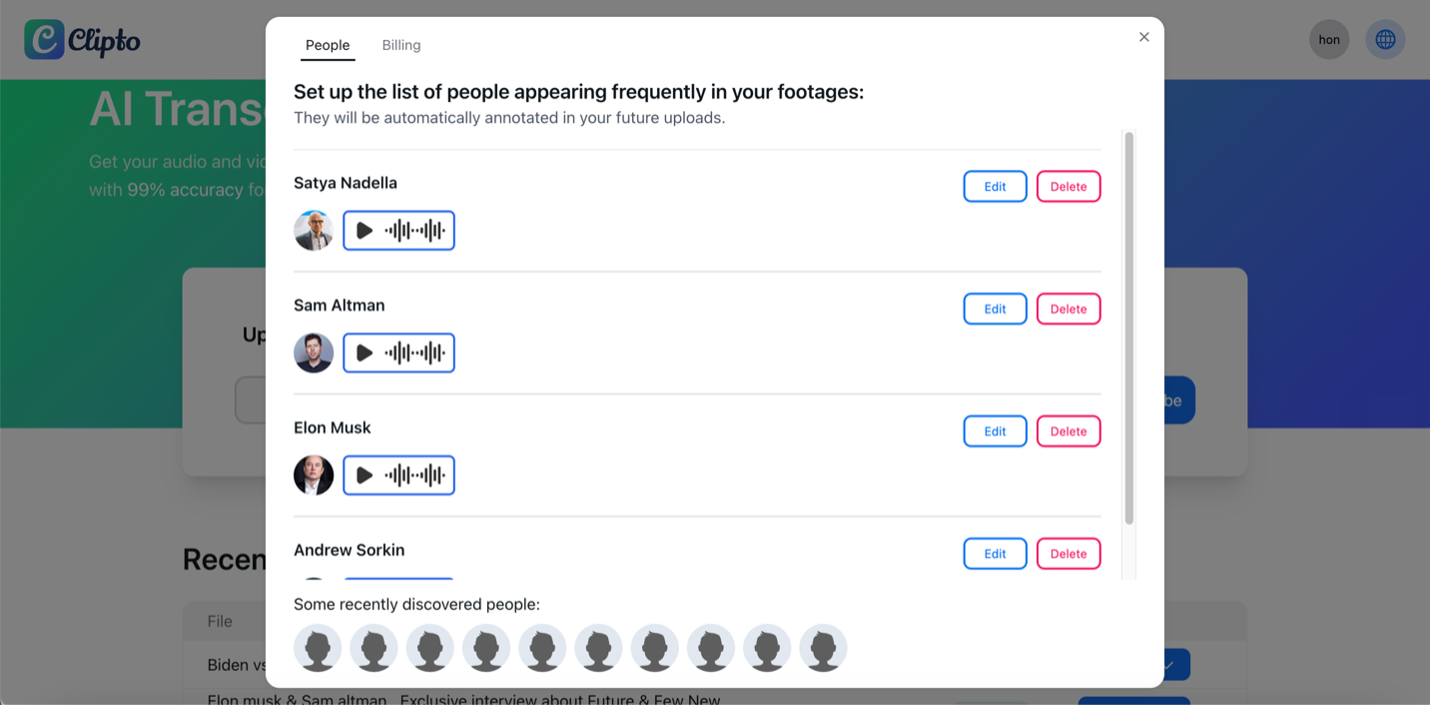
- Managing Speakers in Settings: Only after the first assessment can results be refined further. Clipto’s Settings page enables you to maintain a list of known speakers. However, this is most effective if you regularly record with one set of people, as it helps the system better identify speakers in subsequent recordings.
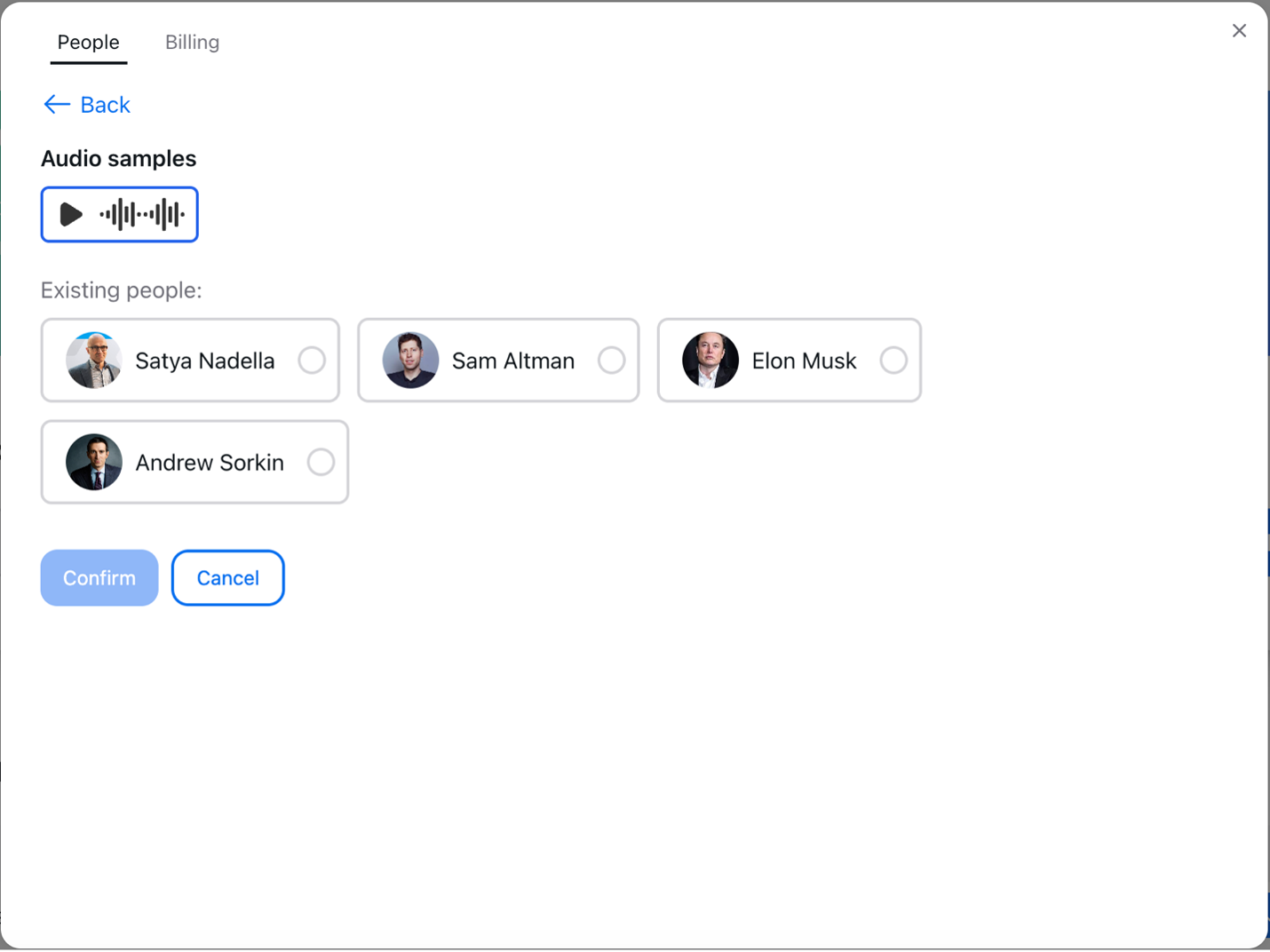
- Assigning or Creating Speaker Profiles: You can assign each new speaker to an existing profile or create a separate one. This process improves the precision of speaker identification in subsequent translation.
- Editing Speaker Information: If you decide to develop a separate speaker profile, Clipto allows you to add your picture and change the name of one speaker. This personalization makes it easier to attribute speakers across separate transcriptions.
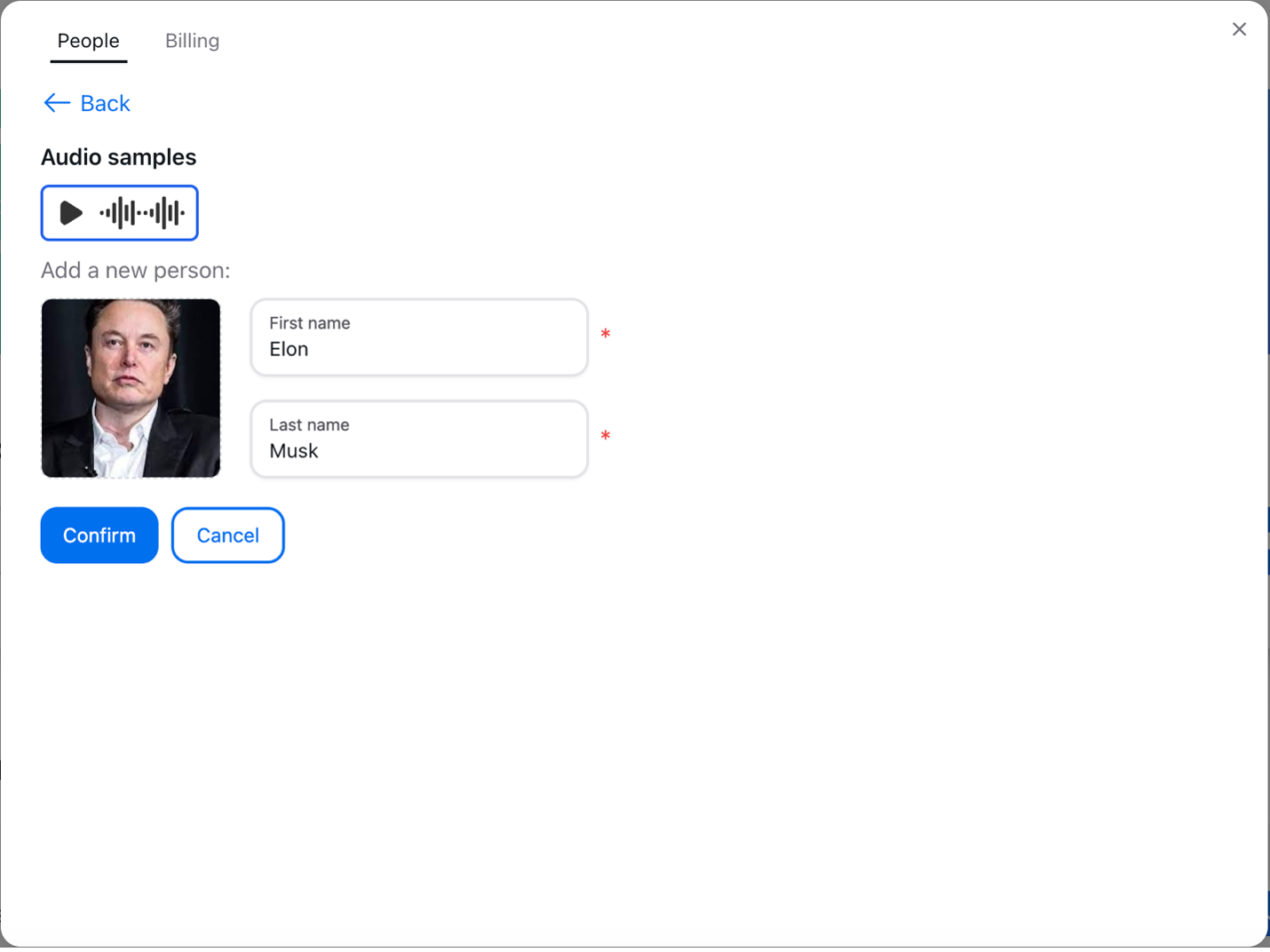
- Reviewing and Editing the Transcript: After the transcription is finished, you can read and correct your script. The interface designed by Clipto is simple and allows you to navigate through the transcript, make corrections, or modify speaker labels if necessary.

Clipto can help facilitate speaker diarization, thus simplifying the transcription process, especially in podcasts and interviews with more than one speaker. Its easy-to-use interface and AI-powered speaker recognition feature make it one of the best tools available for improving the clarity and utility of transcribed material.
Conclusion
Speaker diarization can be seen as a breakthrough in the field of AI transcription, providing an innovative approach to accurately separate and identify speakers in podcasts and interviews, among other formats. Not only does this feature improve the readability of transcription, but it also provides a greater insight into understanding the contexts within which speech happens.
With the world still struggling with many digitized conversations, speaker diarization comparison in different industries cannot only be useful but also necessary. For clarity in communication, compliance with legal situations, insight into business plans and strategies, or sheer accuracy required for academic research, speaker diarization is an indispensable technological tool nowadays.


